Bryon Tjanaka
Publications
Journals
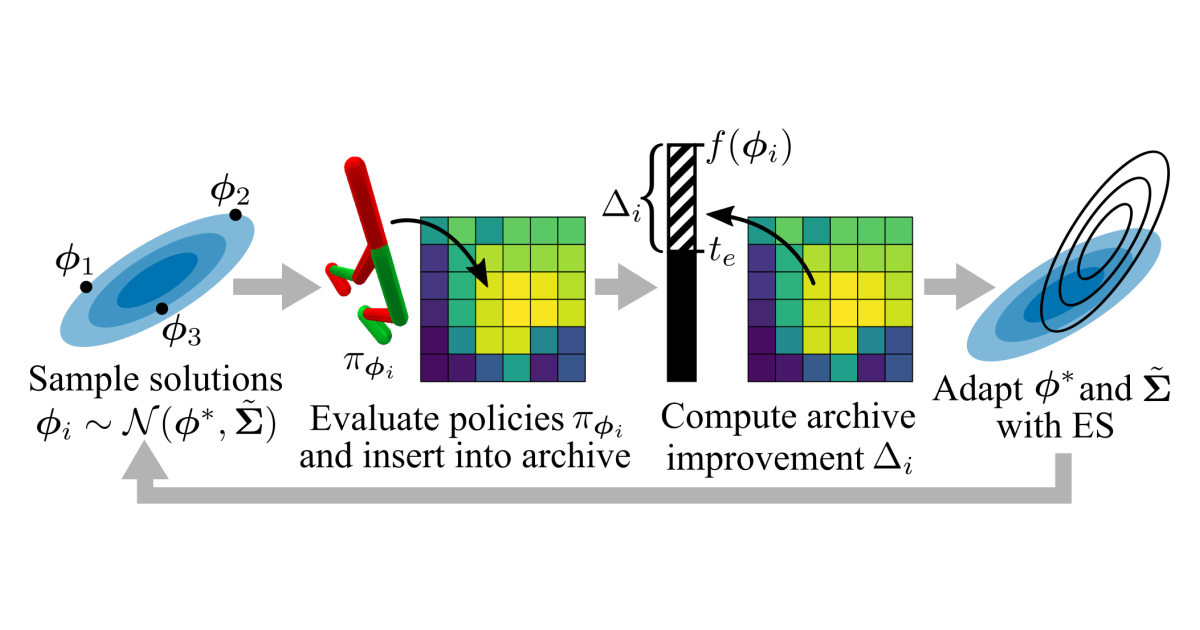
Covariance Matrix Adaptation MAP-Annealing: Theory and Experiments
S. Zhao, , M. C. Fontaine,
ACM Transactions on Evolutionary Learning and Optimization, vol. 5, no. 1, Article 4, March 2025
Abstract
Single-objective optimization algorithms search for the single highest-quality solution with respect to an objective. Quality diversity (QD) optimization algorithms, such as Covariance Matrix Adaptation MAP-Elites (CMA-ME), search for a collection of solutions that are both high-quality with respect to an objective and diverse with respect to specified measure functions. However, CMA-ME suffers from three major limitations highlighted by the QD community: prematurely abandoning the objective in favor of exploration, struggling to explore flat objectives, and having poor performance for low-resolution archives. We propose a new quality diversity algorithm, Covariance Matrix Adaptation MAP-Annealing (CMA-MAE), and its differentiable quality diversity variant, Covariance Matrix Adaptation MAP-Annealing via a Gradient Arborescence (CMA-MAEGA), that address all three limitations. We provide theoretical justifications for the new algorithm with respect to each limitation. Our theory informs our experiments, which support the theory and show that CMA-MAE achieves state-of-the-art performance and robustness on standard QD benchmark and reinforcement learning domains.
Training Diverse High-Dimensional Controllers by Scaling Covariance Matrix Adaptation MAP-Annealing
, M. C. Fontaine, D. H. Lee, A. Kalkar,
Robotics and Automation Letters (RA-L), vol. 8, no. 10, pp. 6771-6778, October 2023, Impact factor: 5.2
Abstract
Pre-training a diverse set of robot controllers in simulation has enabled robots to adapt online to damage in robot locomotion tasks. However, finding diverse, high-performing controllers requires specialized hardware and extensive tuning of a large number of hyperparameters. On the other hand, the Covariance Matrix Adaptation MAP-Annealing algorithm, an evolution strategies (ES)-based quality diversity algorithm, does not have these limitations and has been shown to achieve state-of-the-art performance in standard benchmark domains. However, CMA-MAE cannot scale to modern neural network controllers due to its quadratic complexity. We leverage efficient approximation methods in ES to propose three new CMA-MAE variants that scale to very high dimensions. Our experiments show that the variants outperform ES-based baselines in benchmark robotic locomotion tasks, while being comparable with state-of-the-art deep reinforcement learning-based quality diversity algorithms. Source code and videos are available at https://scalingcmamae.github.io
Conferences
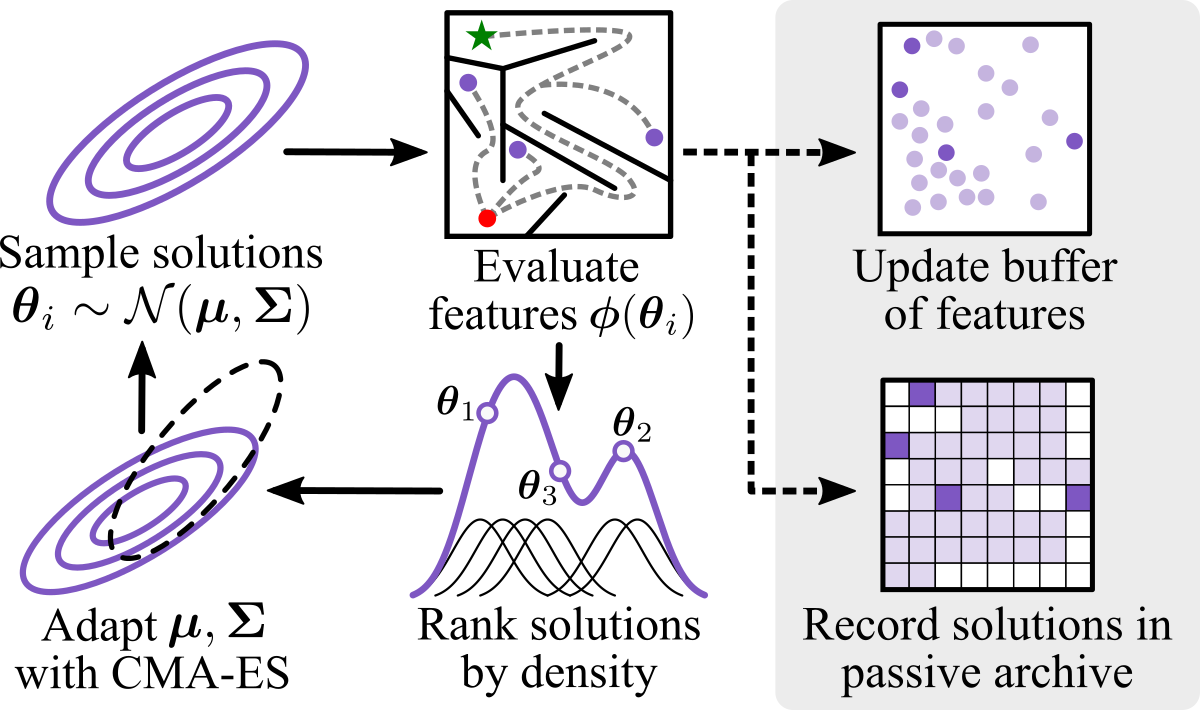
Density Descent for Diversity Optimization
D. H. Lee, A. V. Palaparthi, M. C. Fontaine, ,
Genetic and Evolutionary Computation Conference (GECCO), July 2024, Acceptance rate: 36.0%
Abstract
Diversity optimization seeks to discover a set of solutions that elicit diverse features. Prior work has proposed Novelty Search (NS), which, given a current set of solutions, seeks to expand the set by finding points in areas of low density in the feature space. However, to estimate density, NS relies on a heuristic that considers the $k$-nearest neighbors of the search point in the feature space, which yields a weaker stability guarantee. We propose Density Descent Search (DDS), an algorithm that explores the feature space via CMA-ES on a continuous density estimate of the feature space that also provides a stronger stability guarantee. We experiment with DDS and two density estimation methods: kernel density estimation (KDE) and continuous normalizing flow (CNF). On several standard diversity optimization benchmarks, DDS outperforms NS, the recently proposed MAP-Annealing algorithm, and other state-of-the-art baselines. Additionally, we prove that DDS with KDE provides stronger stability guarantees than NS, making it more suitable for adaptive optimizers. Furthermore, we prove that NS is a special case of DDS that descends a KDE of the feature space.
Proximal Policy Gradient Arborescence for Quality Diversity Reinforcement Learning
S. Batra, , M. C. Fontaine, A. Petrenko, ,
International Conference on Learning Representations (ICLR), May 2024, Spotlight Presentation, Acceptance rate: 5%
Abstract
Training generally capable agents that perform well in unseen dynamic environments is a long-term goal of robot learning. Quality Diversity Reinforcement Learning (QD-RL) is an emerging class of reinforcement learning (RL) algorithms that blend insights from Quality Diversity (QD) and RL to produce a collection of high performing and behaviorally diverse policies with respect to a behavioral embedding. Existing QD-RL approaches have thus far taken advantage of sample-efficient off-policy RL algorithms. However, recent advances in high-throughput, massively parallelized robotic simulators have opened the door for algorithms that can take advantage of such parallelism, and it is unclear how to scale existing off-policy QD-RL methods to these new data-rich regimes. In this work, we take the first steps to combine on-policy RL methods, specifically Proximal Policy Optimization (PPO), that can leverage massive parallelism, with QD, and propose a new QD-RL method with these high-throughput simulators and on-policy training in mind. Our proposed Proximal Policy Gradient Arborescence (PPGA) algorithm yields a 4x improvement over baselines on the challenging humanoid domain.
Surrogate Assisted Generation of Human-Robot Interaction Scenarios
V. Bhatt, H. Nemlekar, M. C. Fontaine, , H. Zhang, Y.-C. Hsu,
Conference on Robot Learning (CoRL), November 2023, Oral Presentation, Acceptance rate: 6.6%
Abstract
As human-robot interaction (HRI) systems advance, so does the difficulty of evaluating and understanding the strengths and limitations of these systems in different environments and with different users. To this end, previous methods have algorithmically generated diverse scenarios that reveal system failures in a shared control teleoperation task. However, these methods require directly evaluating generated scenarios by simulating robot policies and human actions. The computational cost of these evaluations limits their applicability in more complex domains. Thus, we propose augmenting scenario generation systems with surrogate models that predict both human and robot behaviors. In the shared control teleoperation domain and a more complex shared workspace collaboration task, we show that surrogate assisted scenario generation efficiently synthesizes diverse datasets of challenging scenarios. We demonstrate that these failures are reproducible in real-world interactions.
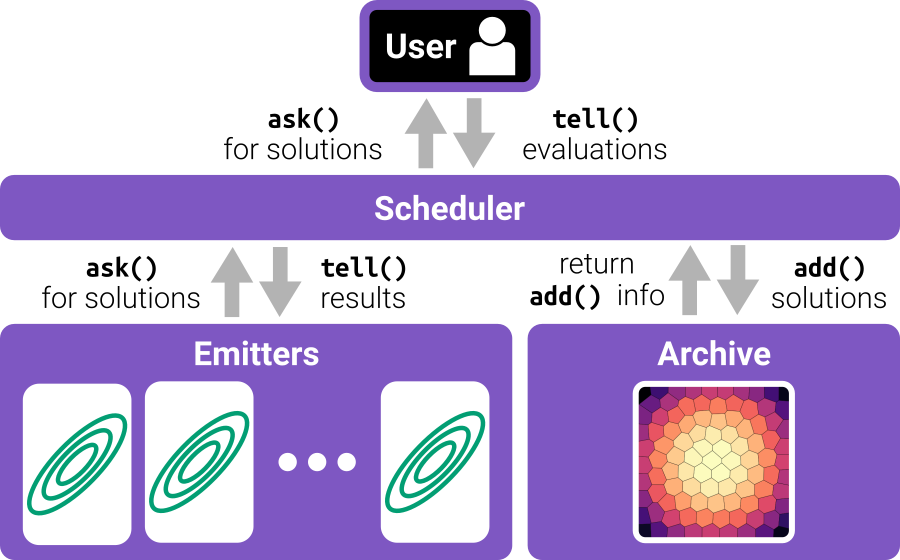
pyribs: A Bare-Bones Python Library for Quality Diversity Optimization
, M. C. Fontaine, D. H. Lee, Y. Zhang, N. R. Balam, N. Dennler, S. S. Garlanka, N. D. Klapsis,
Genetic and Evolutionary Computation Conference (GECCO), July 2023, Acceptance rate: 34.7%
Abstract
Recent years have seen a rise in the popularity of quality diversity (QD) optimization, a branch of optimization that seeks to find a collection of diverse, high-performing solutions to a given problem. To grow further, we believe the QD community faces two challenges: developing a framework to represent the field's growing array of algorithms, and implementing that framework in software that supports a range of researchers and practitioners. To address these challenges, we have developed pyribs, a library built on a highly modular conceptual QD framework. By replacing components in the conceptual framework, and hence in pyribs, users can compose algorithms from across the QD literature; equally important, they can identify unexplored algorithm variations. Furthermore, pyribs makes this framework simple, flexible, and accessible, with a user-friendly API supported by extensive documentation and tutorials. This paper overviews the creation of pyribs, focusing on the conceptual framework that it implements and the design principles that have guided the library's development.
Deep Surrogate Assisted Generation of Environments
V. Bhatt*, , M. C. Fontaine*,
Neural Information Processing Systems (NeurIPS), November 2022, Acceptance rate: 25.6%
Abstract
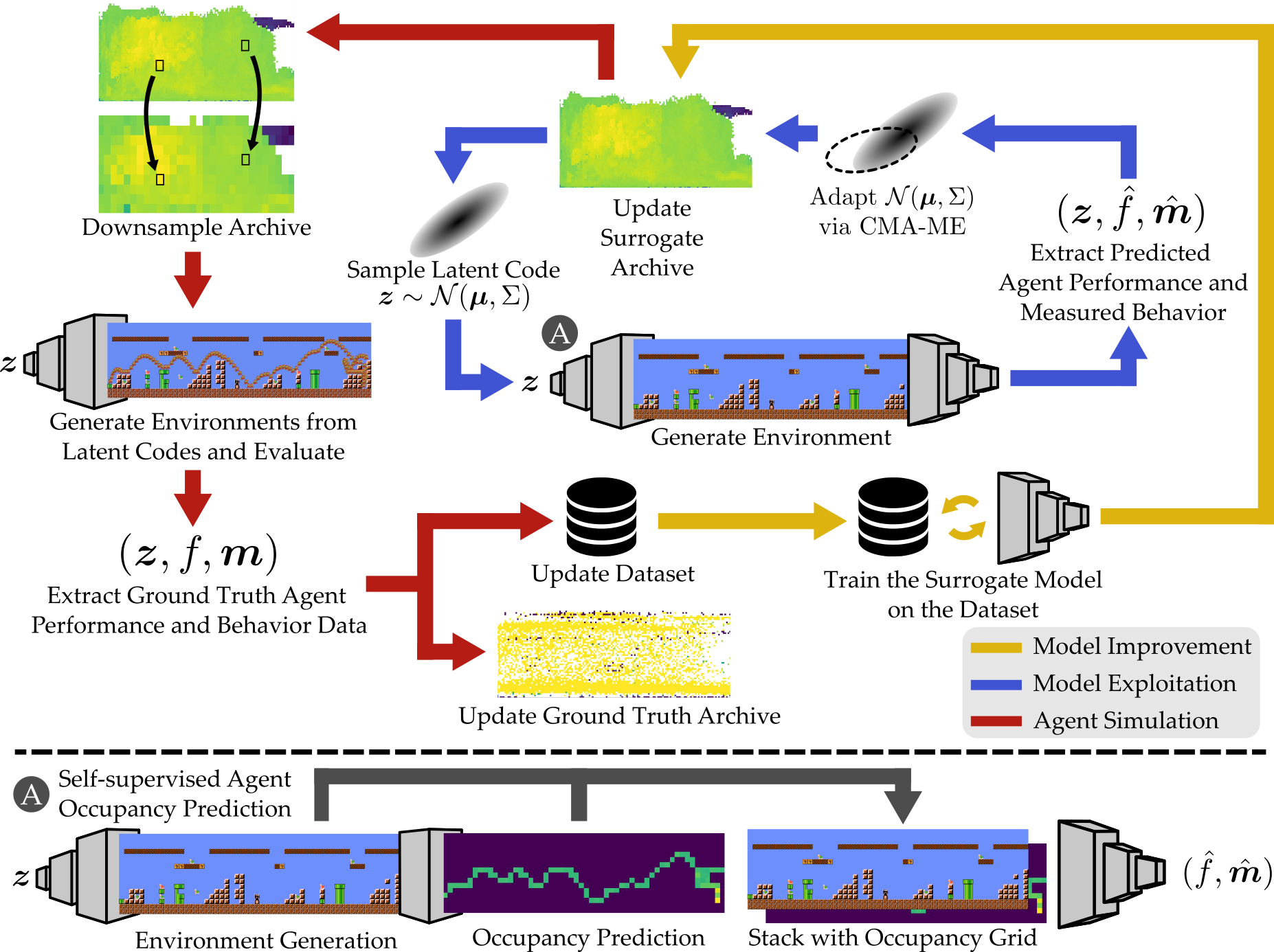
Recent progress in reinforcement learning (RL) has started producing generally capable agents that can solve a distribution of complex environments. These agents are typically tested on fixed, human-authored environments. On the other hand, quality diversity (QD) optimization has been proven to be an effective component of environment generation algorithms, which can generate collections of high-quality environments that are diverse in the resulting agent behaviors. However, these algorithms require potentially expensive simulations of agents on newly generated environments. We propose Deep Surrogate Assisted Generation of Environments (DSAGE), a sample-efficient QD environment generation algorithm that maintains a deep surrogate model for predicting agent behaviors in new environments. Results in two benchmark domains show that DSAGE significantly outperforms existing QD environment generation algorithms in discovering collections of environments that elicit diverse behaviors of a state-of-the-art RL agent and a planning agent. Our source code and videos are available at https://dsagepaper.github.io/
Approximating Gradients for Differentiable Quality Diversity in Reinforcement Learning
, M. C. Fontaine, J. Togelius,
Genetic and Evolutionary Computation Conference (GECCO), July 2022, Acceptance rate: 37%
Abstract
Consider the problem of training robustly capable agents. One approach is to generate a diverse collection of agent polices. Training can then be viewed as a quality diversity (QD) optimization problem, where we search for a collection of performant policies that are diverse with respect to quantified behavior. Recent work shows that differentiable quality diversity (DQD) algorithms greatly accelerate QD optimization when exact gradients are available. However, agent policies typically assume that the environment is not differentiable. To apply DQD algorithms to training agent policies, we must approximate gradients for performance and behavior. We propose two variants of the current state-of-the-art DQD algorithm that compute gradients via approximation methods common in reinforcement learning (RL). We evaluate our approach on four simulated locomotion tasks. One variant achieves results comparable to the current state-of-the-art in combining QD and RL, while the other performs comparably in two locomotion tasks. These results provide insight into the limitations of current DQD algorithms in domains where gradients must be approximated. Source code is available at https://github.com/icaros-usc/dqd-rl.

On the Importance of Environments in Human-Robot Coordination
M. C. Fontaine*, Y.-C. Hsu*, Y. Zhang*, ,
Robotics: Science and Systems (RSS), July 2021, Acceptance rate: 27%
Abstract
When studying robots collaborating with humans, much of the focus has been on robot policies that coordinate fluently with human teammates in collaborative tasks. However, less emphasis has been placed on the effect of the environment on coordination behaviors. To thoroughly explore environments that result in diverse behaviors, we propose a framework for procedural generation of environments that are (1) stylistically similar to human-authored environments, (2) guaranteed to be solvable by the human-robot team, and (3) diverse with respect to coordination measures. We analyze the procedurally generated environments in the Overcooked benchmark domain via simulation and an online user study. Results show that the environments result in qualitatively different emerging behaviors and statistically significant differences in collaborative fluency metrics, even when the robot runs the same planning algorithm.
Software
pyribs: A bare-bones Python library for quality diversity optimization
, M. C. Fontaine, D. H. Lee, Y. Zhang, T. T. M. Vu, S. Sommerer, N. Dennler,
GitHub repository, February 2021
Abstract
A bare-bones Python library for quality diversity (QD) optimization. Pyribs implements the highly modular Rapid Illumination of Behavior Space (RIBS) framework for QD optimization. Pyribs is also the official implementation of Covariance Matrix Adaptation MAP-Elites (CMA-ME), Covariance Matrix Adaptation MAP-Elites via a Gradient Arborescence (CMA-MEGA), Covariance Matrix Adaptation MAP-Annealing (CMA-MAE), and scalable variants of CMA-MAE.

Short Papers
Quality Diversity for Robot Learning: Limitations and Future Directions
S. Batra, , ,
Genetic And Evolutionary Computation Conference (GECCO) Companion, July 2024
Abstract
Quality Diversity (QD) has shown great success in discovering high-performing, diverse policies for robot skill learning. While current benchmarks have led to the development of powerful QD methods, we argue that new paradigms must be developed to facilitate open-ended search and generalizability. In particular, many methods focus on learning diverse agents that each move to a different $xy$ position in MAP-Elites-style bounded archives. Here, we show that such tasks can be accomplished with a single, goal-conditioned policy paired with a classical planner, achieving $O(1)$ space complexity w.r.t. the number of policies and generalization to task variants. We argue that this approach is successful because it extracts task-invariant structural knowledge by modeling a relational graph between adjacent cells in the archive. We motivate this view with emerging evidence from computational neuroscience and explore connections between QD and models of cognitive maps in human and other animal brains. We conclude with a discussion exploring the relationships between QD and cognitive maps, and propose future research directions inspired by cognitive maps towards future generalizable algorithms capable of truly open-ended search.
Workshops
Scaling Covariance Matrix Adaptation MAP-Annealing to High-Dimensional Controllers
, M. C. Fontaine, A. Kalkar,
Southern California Robotics Symposium, September 2023
Abstract
Pre-training a diverse set of robot controllers in simulation has enabled robots to adapt online to damage in robot locomotion tasks. However, finding diverse, high-performing controllers requires specialized hardware and extensive tuning of a large number of hyperparameters. On the other hand, the Covariance Matrix Adaptation MAP-Annealing algorithm, an evolution strategies (ES)-based quality diversity algorithm, does not have these limitations and has been shown to achieve state-of-the-art performance in standard benchmark domains. However, CMA-MAE cannot scale to modern neural network controllers due to its quadratic complexity. We leverage efficient approximation methods in ES to propose three new CMA-MAE variants that scale to very high dimensions. Our experiments show that the variants outperform ES-based baselines in benchmark robotic locomotion tasks, while being comparable with state-of-the-art deep reinforcement learning-based quality diversity algorithms. Source code and videos are available at https://scalingcmamae.github.io
Scaling Covariance Matrix Adaptation MAP-Annealing to High-Dimensional Controllers
, M. C. Fontaine, A. Kalkar,
Deep Reinforcement Learning Workshop at NeurIPS 2022, December 2022
Abstract
Pre-training a diverse set of robot controllers in simulation has enabled robots to adapt online to damage in robot locomotion tasks. However, finding diverse, high-performing controllers requires specialized hardware and extensive tuning of a large number of hyperparameters. On the other hand, the Covariance Matrix Adaptation MAP-Annealing algorithm, an evolution strategies (ES)-based quality diversity algorithm, does not have these limitations and has been shown to achieve state-of-the-art performance in standard benchmark domains. However, CMA-MAE cannot scale to modern neural network controllers due to its quadratic complexity. We leverage efficient approximation methods in ES to propose three new CMA-MAE variants that scale to very high dimensions. Our experiments show that the variants outperform ES-based baselines in benchmark robotic locomotion tasks, while being comparable with state-of-the-art deep reinforcement learning-based quality diversity algorithms. Source code and videos are available at https://scalingcmamae.github.io
Differentiable Quality Diversity for Reinforcement Learning by Approximating Gradients
, M. C. Fontaine, J. Togelius,
Southern California Robotics Symposium, September 2022
Abstract
Consider the problem of training robustly capable agents. One approach is to generate a diverse collection of agent polices. Training can then be viewed as a quality diversity (QD) optimization problem, where we search for a collection of performant policies that are diverse with respect to quantified behavior. Recent work shows that differentiable quality diversity (DQD) algorithms greatly accelerate QD optimization when exact gradients are available. However, agent policies typically assume that the environment is not differentiable. To apply DQD algorithms to training agent policies, we must approximate gradients for performance and behavior. We propose two variants of the current state-of-the-art DQD algorithm that compute gradients via approximation methods common in reinforcement learning (RL). We evaluate our approach on four simulated locomotion tasks. One variant achieves results comparable to the current state-of-the-art in combining QD and RL, while the other performs comparably in two locomotion tasks. These results provide insight into the limitations of current DQD algorithms in domains where gradients must be approximated. Source code is available at https://github.com/icaros-usc/dqd-rl.
Quantifying Efficiency in Quality Diversity Optimization
, M. C. Fontaine,
Workshop on Benchmarks for Quality-Diversity Algorithms at GECCO 2022, July 2022
Abstract
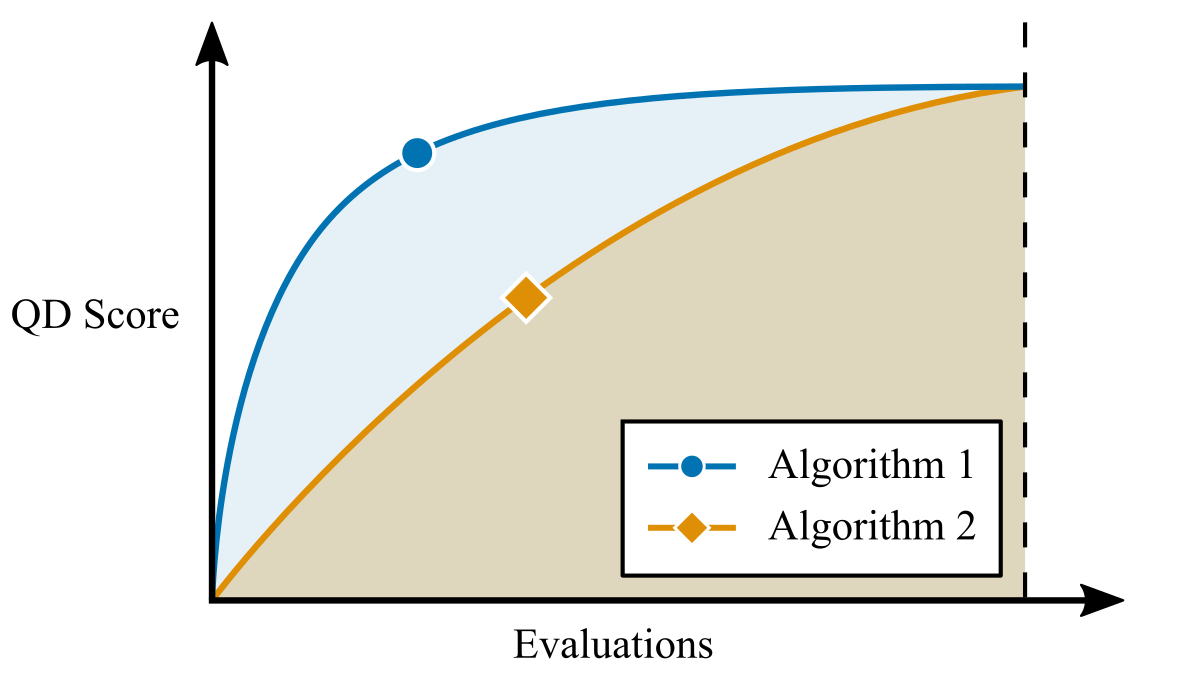
In quality diversity (QD) optimization, the QD score is a holistic metric which sums the objective values of all cells in the archive. Since the QD score only measures the performance of a QD algorithm at a single point in time, it fails to reflect algorithm efficiency. Two algorithms may have the same QD score even though one algorithm achieved that score with fewer evaluations. We propose a metric called "QD score AUC" which quantifies this efficiency.
Differentiable Quality Diversity for Reinforcement Learning by Approximating Gradients
, M. C. Fontaine, J. Togelius,
Workshop on Agent Learning in Open-Endedness (ALOE) at ICLR 2022, April 2022, Spotlight Paper
Abstract
Consider the problem of training robustly capable agents. One approach is to generate a diverse collection of agent polices. Training can then be viewed as a quality diversity (QD) optimization problem, where we search for a collection of performant policies that are diverse with respect to quantified behavior. Recent work shows that differentiable quality diversity (DQD) algorithms greatly accelerate QD optimization when exact gradients are available. However, agent policies typically assume that the environment is not differentiable. To apply DQD algorithms to training agent policies, we must approximate gradients for performance and behavior. We propose two variants of the current state-of-the-art DQD algorithm that compute gradients via approximation methods common in reinforcement learning (RL). We evaluate our approach on four simulated locomotion tasks. One variant achieves results comparable to the current state-of-the-art in combining QD and RL, while the other performs comparably in two locomotion tasks. These results provide insight into the limitations of current DQD algorithms in domains where gradients must be approximated. Source code is available at https://github.com/icaros-usc/dqd-rl.
Prior to Joining USC
Scalable Hierarchical Agglomerative Clustering
N. Monath*, K. A. Dubey, G. Guruganesh, M. Zaheer, A. Ahmed, A. McCallum, G. Mergen, M. Najork, M. Terzihan, , ,
27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, August 2021
Abstract
The applicability of agglomerative clustering, for inferring both hierarchical and flat clustering, is limited by its scalability. Existing scalable hierarchical clustering methods sacrifice quality for speed and often lead to over-merging of clusters. In this paper, we present a scalable, agglomerative method for hierarchical clustering that does not sacrifice quality and scales to billions of data points. We perform a detailed theoretical analysis, showing that under mild separability conditions our algorithm can not only recover the optimal flat partition but also provide a two-approximation to non-parametric DP-Means objective. This introduces a novel application of hierarchical clustering as an approximation algorithm for the non-parametric clustering objective. We additionally relate our algorithm to the classic hierarchical agglomerative clustering method. We perform extensive empirical experiments in both hierarchical and flat clustering settings and show that our proposed approach achieves state-of-the-art results on publicly available clustering benchmarks. Finally, we demonstrate our method's scalability by applying it to a dataset of 30 billion queries. Human evaluation of the discovered clusters show that our method finds better quality of clusters than the current state-of-the-art.
Development and Benchmarking of Open Force Field v1.0.0 — the Parsley Small-Molecule Force Field
Y. Qiu, D. G. A. Smith, S. Boothroyd, H. Jang, D. F. Hahn, J. Wagner, C. C. Bannan, T. Gokey, V. T. Lim, C. D. Stern, A. Rizzi, , G. Tresadern, X. Lucas, M. R. Shirts, M. K. Gilson, J. D. Chodera, C. I. Bayly, D. L. Mobley, L.-P. Wang
Journal of Chemical Theory and Computation, October 2021
Abstract
We present a methodology for defining and optimizing a general force field for classical molecular simulations, and we describe its use to derive the Open Force Field 1.0.0 small-molecule force field, codenamed Parsley. Rather than using traditional atom typing, our approach is built on the SMIRKS-native Open Force Field (SMIRNOFF) parameter assignment formalism, which handles increases in the diversity and specificity of the force field definition without needlessly increasing the complexity of the specification. Parameters are optimized with the ForceBalance tool, based on reference quantum chemical data that include torsion potential energy profiles, optimized gas-phase structures, and vibrational frequencies. These quantum reference data are computed and are maintained with QCArchive, an open-source and freely available distributed computing and database software ecosystem. In this initial application of the method, we present essentially a full optimization of all valence parameters and report tests of the resulting force field against compounds and data types outside the training set. These tests show improvements in optimized geometries and conformational energetics and demonstrate that Parsley's accuracy for liquid properties is similar to that of other general force fields, as is accuracy on binding free energies. We find that this initial Parsley force field affords accuracy similar to that of other general force fields when used to calculate relative binding free energies spanning 199 protein–ligand systems. Additionally, the resulting infrastructure allows us to rapidly optimize an entirely new force field with minimal human intervention.
Miscellaneous
Contact
Make a business card that links to a website with all your contact info! Presented at Eleventies 2021.
November 2021