
Bryon Tjanaka
News
Discount Model Search has been accepted to ICLR 2026 as an Oral Presentation!
February 5, 2026
I have defended my Ph.D. and graduated from USC! Next, I will be joining Waymo. My dissertation is available here.
December 2025
Show more
Today I will present pyribs: A Bare-Bones Python Library for Quality Diversity Optimization at GECCO 2023!
July 17, 2023
I have received an NVIDIA Academic Hardware Grant.
March 10, 2022
I have received an NSF Graduate Research Fellowship.
March 23, 2021
Download pyribs, a quality diversity library I released with ICAROS.
February 5, 2021
I have started my Ph.D. at USC.
August 24, 2020
Selected Publications
Discount Model Search for Quality Diversity Optimization in High-Dimensional Measure Spaces
, H. Chen, M. C. Fontaine,
International Conference on Learning Representations (ICLR), April 2026
Oral Presentation, Acceptance rate: 1.13%Abstract
Quality diversity (QD) optimization searches for a collection of solutions that optimize an objective while attaining diverse outputs of a user-specified, vector-valued measure function. Contemporary QD algorithms are typically limited to low-dimensional measures because high-dimensional measures are prone to distortion, where many solutions found by the QD algorithm map to similar measures. For example, the state-of-the-art CMA-MAE algorithm guides measure space exploration with a histogram in measure space that records so-called discount values. However, CMA-MAE stagnates in domains with high-dimensional measure spaces because solutions with similar measures fall into the same histogram cell and hence receive the same discount value. To address these limitations, we propose Discount Model Search (DMS), which guides exploration with a model that provides a smooth, continuous representation of discount values. In high-dimensional measure spaces, this model enables DMS to distinguish between solutions with similar measures and thus continue exploration. We show that DMS facilitates new capabilities for QD algorithms by introducing two new domains where the measure space is the high-dimensional space of images, which enables users to specify their desired measures by providing a dataset of images rather than hand-designing the measure function. Results in these domains and on high-dimensional benchmarks show that DMS outperforms CMA-MAE and other existing black-box QD algorithms.

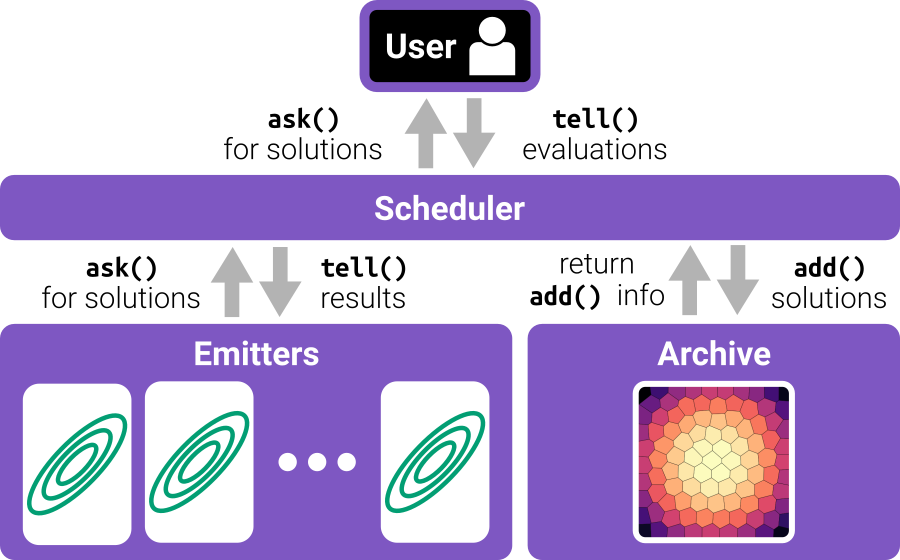
pyribs: A Bare-Bones Python Library for Quality Diversity Optimization
, M. C. Fontaine, D. H. Lee, Y. Zhang, N. R. Balam, N. Dennler, S. S. Garlanka, N. D. Klapsis,
Genetic and Evolutionary Computation Conference (GECCO), July 2023, Acceptance rate: 34.7%
Abstract
Recent years have seen a rise in the popularity of quality diversity (QD) optimization, a branch of optimization that seeks to find a collection of diverse, high-performing solutions to a given problem. To grow further, we believe the QD community faces two challenges: developing a framework to represent the field's growing array of algorithms, and implementing that framework in software that supports a range of researchers and practitioners. To address these challenges, we have developed pyribs, a library built on a highly modular conceptual QD framework. By replacing components in the conceptual framework, and hence in pyribs, users can compose algorithms from across the QD literature; equally important, they can identify unexplored algorithm variations. Furthermore, pyribs makes this framework simple, flexible, and accessible, with a user-friendly API supported by extensive documentation and tutorials. This paper overviews the creation of pyribs, focusing on the conceptual framework that it implements and the design principles that have guided the library's development.
Approximating Gradients for Differentiable Quality Diversity in Reinforcement Learning
, M. C. Fontaine, J. Togelius,
Genetic and Evolutionary Computation Conference (GECCO), July 2022, Acceptance rate: 37%
Abstract
Consider the problem of training robustly capable agents. One approach is to generate a diverse collection of agent polices. Training can then be viewed as a quality diversity (QD) optimization problem, where we search for a collection of performant policies that are diverse with respect to quantified behavior. Recent work shows that differentiable quality diversity (DQD) algorithms greatly accelerate QD optimization when exact gradients are available. However, agent policies typically assume that the environment is not differentiable. To apply DQD algorithms to training agent policies, we must approximate gradients for performance and behavior. We propose two variants of the current state-of-the-art DQD algorithm that compute gradients via approximation methods common in reinforcement learning (RL). We evaluate our approach on four simulated locomotion tasks. One variant achieves results comparable to the current state-of-the-art in combining QD and RL, while the other performs comparably in two locomotion tasks. These results provide insight into the limitations of current DQD algorithms in domains where gradients must be approximated. Source code is available at https://github.com/icaros-usc/dqd-rl.
